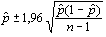 , där n är storleken på stickprovet och
p-tak den beräknade andelen. Värdet 1,96 ger
konfidensintervallet för en sannolikhet på 95%.
, där n är storleken på stickprovet och
p-tak den beräknade andelen. Värdet 1,96 ger
konfidensintervallet för en sannolikhet på 95%.
ABSTRAKT: Författaren beskriver en utopisk framtida informationsmiljö. Fem egenskaper hos en sådan miljö identifieras: intelligens, anpassningsförmåga, utvecklingsbarhet, lärande och kooperativitet. En enkätundersökning utfördes för att mäta inställningen till dessa egenskaper hos 95 forskare, vilka visat ett speciellt intresse för informationsteknologi. Resultatet visade att endast 27% (±16%) ser positivt på den beskrivna utopin. Men de flesta forskare var positivt inställda till intelligenta och utvecklingsbara program.
Uppsatsens syfte är att undersöka forskares inställning till några specifika egenskaper hos ett informationssystem. Undersökningen begränsar sig till forskare med speciellt intresse för informationsteknologi. De specifika egenskaperna är sådana som författaren har ett speciellt intresse för. Med informationsmiljö menas alla de verktyg och sätt som används för att söka, ta till sig, bearbeta och sprida information.
Min dröm är en värld där jag direkt kan få vad jag önskar, allt snabbt som tanken. Att nå information om en sak ska inte ta längre tid än att formulera just vad det är man vill veta. Att skapa något ska inte kräva mer arbete än att beskriva vad man vill ha. Livet blir då ett skapande äventyr. Tillsammans målar vi vackra landskap med våran tankevärld.
Genom hela historien, ur vårt perspektiv, har mycket tid ägnats åt att förvalta gammal kunskap; att upprätthålla normaltillståndet / överleva. Med nya verktyg (boktryckarkonsten - WWW) har gamla repetitiva uppgifter tagit allt mindre tid. Vi flyttar fram våra positioner tack vara dessa nya verktyg. Men den plats där vi då befinner oss i är lika kaotisk som alltid. Det är ett ständigt sorterande av oordnat material, nivå efter nivå, område efter område. Att skapa vackra saker av kaos, är något vi alla gör; forskaren med sina motstridiga hypoteser, konstnären med sitt möte med livet och alla hantverkare, gatsopare, osv.
Den enorma vetskapsmängden fördubblas med allt snabbare takt. Med verktygens ökade effektivitet blir kärnan i aktiviteterna mer framträdande. Vi organiserar, preciserar och definierar vetskapen. Vår strävan är att finna verktyg som minskar motståndet i det skapande arbetet. Detta är vad jag tror.
Denna uppsats vill undersöka en vision. Visionen är min egen. Begrepp och beskrivningssätt är mina egna. Jag har inte lyckats finna någon annan undersökning om forskares vision av den utopiska informationsmiljön. Däremot finns det många andra som har visioner om framtidens informationsmiljö. Theodor (Ted) H Nelson, myntare av ordet hypertext, beskriver sina visioner i sin bok "Literary Machines" (1992). Han inspirerades i sin tur av Vannevar Bush's artikel "As We May Think" (1945). En annan tidig visionär, J C R Licklider (1960), skrev:
There are many man-machine systems. At present, however, there are no man-computer symbioses. The hope is that, in not to many years, human brains and computing machines will be coupled together very tightly, and that the resulting partnership will think as no human being has ever thought.
Ivan Sutherlann skrev redan 1965, dvs långt före Star Treks Holodeck, i "The ultimate display" (1965):
The ultimate display would ... be a room within which the computer can control the existence of matter. A chair displayed in such a room would be good enough to sit in. Handcuffs displayed in such a room would be confining, and a bullet displayed in such a room would be fatal. With appropriate programming such a display could literally be the Wonderland in which Alice walked.
Virtual Reality och användargränssnitt finns det mycket skrivet om. I "Mirror Worlds - or: the day software puts the universe in a shoebox... how it will happen and what it will mean" skriver David Gelernter (1991) om hur mycket enklare vi skulle kunna ta åt oss information genom att hela världen grafiskt simuleras för våra sinnen. Detta kan bli verklighet. William H (Bill) Gates III, delägare i ett framgångsrikt mjukvaruföretag, skriver (1996):
I have lots of people working on all of these things. When the computer can see you, recognize you, respond to your speech and gestures and things like that, then it becomes much more pervasive in how it fits into your environment and how you can use it as an information tool.
Jag vill här fokusera på en liten del av denna framtidsvision. Jag kan tänka mig några olika områden där typen av krav på informationsmiljön är olika. Vi kan tänka oss en hobby (exempelvis Sveriges hundintresse), ett forskningsområde (artificiell intelligens), en administration (sjukhusjournaler), ett projekt (utveckla en ny tandkräm), en politisk diskussion eller intresseorganisation (miljön).
Dessa områden kan var och en leda till olika behov hos användarna och därmed kräva olika lösningar. Därför måste vi, för att beskriva hur en önskvärd framtida informationsmiljö, veta för vilket område miljön är tänkt att passa. Den uppdelning jag gjort här är min egen.
Detta innefattar en obegränsad mängd människor med en gemensam aktivitet, där det är aktiviteten (att ha hund) snarare än informations-skapandet / -intagandet som är det centrala. De aktiva på området utvecklar förmodligen ett intresse för fakta av olika slag, men det är aktiviteten som är kärnan. Mycket av informationen kan betraktas som informationssamling (Hundmat, träningstips, beskrivning av olika raser, etc).
Detta innefattar en obegränsad mängd människor med ett gemensamt intresse av att utvidga vetskapen / förståelsen av ett område. Aktiviteterna är riktade mot att utvidga vetskapen. Alla inblandade har intresse av att förfina själva informationsinneållet. Informationsinnehållet utgörs huvudsakligen av en kontinuerlig diskussion om vad vi vet. Med det menar jag att de enskilda forskarnas arbeten ingår i en kontext av andra forskningsrapporter och ett flöde av tidskriftsartiklar och seminarier, där forskningsområdet utforskas och definieras. Detta kan ställas i kontrast till hobbyn, där informationen består av pris på hundkoppel, skötseltips, etc.
Detta innefattar en begränsad grupp människor inom ett område som genom sina aktiviteter ska uppnå väldefinierade mål på regelbunden basis. I en traditionell administration finns det inget intresse för nyskapande. Ansvarsfördelning mellan de inblandade är väldefinierad. De vill nå information för sina beslut och de producerar information som ska ha vissa kvaliteter. Mycket av informationen kan betraktas som faktasamling.
Detta innefattar en begränsad grupp människor inom ett område som vill uppnå ett visst mål. Målet är det viktigaste. De inblandade kan ha olika roller i genomförandet. Området är relativt avgränsat. Under formgivandet av detaljerna i målet behöver de inblandade tillgång till information och producerar ny information. Informationsmängden växer snabbt. Var och en av de inblandade har en del i hur målet ska uppnås och är motiverade att bidraga i det kreativa uppbyggandet, på sitt område.
Detta innefattar en obegränsad mängd människor med olika värderingar och mål. Det finns mycket att diskutera i vilka praktiska lösningar som tillmötesgår vilka värderingar. Alla inblandade är intresserade av att nå fram till eller förmedla en åsikt. En del av de intresserade vill även producera informationen som behövs för att uppnå sina mål. Aktiviteten består i huvudsak av att sprida information / åsikter om vad de vill förändra.
| Aktivitet Information | Vetskap Diskussion | |
|---|---|---|
| Obegränsad | Hobby | Forskning |
| Politisk diskussion och Intresseorganisation | ||
| Begränsad | Administration | Projekt |
Det finns givetvis inga skarpa gränser mellan de olika sorterna av intresse.
De webbsidor jag har behandlar ett område som skulle kunna betraktas som delvis hobby och delvis forskning. Det är kanske därför jag är speciellt intresserad av dessa två områden.
Forskningens diskussionskaraktär gör att en analys av området kan bli ganska abstrakt. å andra sidan är de inblandades aktiviteter, förväntningar och mål ganska avgränsade. Här finns även ett visst inslag av aktivitetssamordnande. Hobbyn har en faktakaraktär. De inblandade vill få snabb information om detaljer som behövs för utövandet av deras aktivitet. De efterfrågade detaljerna (så som priser på hundkoppel) kan belysas ur olika perspektiv och en del personer kan ha ett intresse att föra en diskussion om dessa detaljer. En annan stor del är samordnandet av själva aktiviteterna plus att systemet används under aktiviteternas gång (som en handdator som under hundpromenaden visar på en karta var andra hundar befinner sig). Det handlar om produktinformation, kalendrar och instruktionsböcker av olika slag. De inblandades intresse av att bidraga varierar. De flesta vill bara ha informationen ("vad kostar kopplet?"), medan andra vill dela med sig information ("det där kopplet gick sönder efter två dagar, köp det inte!"). Detta kan ställas i kontrast till forskningen där alla inblandade har ett intresse av att bidraga med information.
Jag väljer att fokusera på forskningsområdet, eftersom dess önskemål kan ses som en delmängd av hobby-området.
Varje forskare har sina egna begreppskonstellationer han är speciellt intresserad av. Han är intresserad av undersökningar och diskussioner som är relevanta för hans intresse. Den information som endast delvis berör intresset, ska (automatiskt) omarbetas för att formuleras ur forskarens intresseperspektiv.
Forskaren ska få den information han vill ha, allt eftersom den dyker upp. Varje begreppskonstellation kan beskrivas i finare detalj som ett antal delfrågor. Informationsmiljön är bekant med forskarens generella intressen. Med forskarens fortskridande aktiviteter i informationsmiljön, förändras hans begreppskonstellationsprofil på så vis att informationsflödet ständigt anpassas efter de frågor han är intresserad av. Forskaren vill inte spendera någon tid eller kraft på att explicit beskriva för informationsmiljön vad det är han är intresserad av.
Forskaren vill få svar på frågor med minsta möjliga ansträngning. är svaret komplext betyder det att presentationen behöver ha en större omfattning. Inte nog med att presentationen ska ge precis det svar han vill ha. Den ska även anpassas efter vad forskaren redan vet, vilken inlärningsstil han har, på vilket sätt han gillar att lära sig (läsning, video, övningar, diskussion, etc), mm. Presentationen ska undvika att beskriva sådant forskaren redan vet, samtidigt som den ska presenteras med hjälp av de begrepp han redan känner till, så att den nya kunskapen kan effektivt kan integreras med den redan existerande. även andra detaljer av intresse kan vävas in för att ge forskaren en rikare förståelse av begreppskonstellationen.
Då en fråga kan förväntas (för forskaren) leda till följdfrågor, organiseras presentationen för att på bästa sätt besvara både den ursprungliga frågan samt följdfrågorna, så att det samlade resultatet blir så bra som möjligt. Det betyder andra frågor vävs in i presentationen främst för att effektivisera förväntade följande presentationer.
Gregory Rawlins beskriver i sin bok "Moths to the Flame - The Seductions of Computer Technology" om mycket snarlika scenarion:
Paper books can't talk to libraries and other information sources; so today's authors have to first think up possible questions, research the answers, then find ways to summarize them in print. With electronic books, the reader could pose the questions - questions the auther may not even have thought of - the book could research the answers - perhaps almost as well as the author - and let the reader decide how best to display the information. Such books might increas comprehension, retention, and emotional response by combining the best aspects of lectures, television, computers, and print. (s 54)
Presentation ska utformas efter de ändamål forskaren har. Den anpassas efter den tid forskaren har till sitt förfogande och förändras dynamiskt utifrån nya frågor, prioriteringar och tidsramar. Ska forskaren ha en "produkt" klar till en viss tidpunkt måste de presentationer forskaren begär anpassas så att han hinner ta till sig den information han behöver för att slutföra sitt arbete.
Detta är den önskvärda miljön. I denna uppsats har jag valt att fokusera på vad forskaren kan tänkas vilja ha. Hur denna informationsmiljö tekniskt kan konstrueras är en annan fråga. Jag har även valt att inte gå in på hur kvaliteten på informationen kan garanteras eller hur vi ska våga lita på den information som presenteras.
En beskrivning av hur denna informationsmiljö kan te sig för forskaren måste inbegripa spekulationer om vad som är möjligt. Jag tror att vi ständigt kan komma allt närmare målet, men aldrig ända fram. Skulle vi kunna få alla svar utan ansträngning skulle det inte finnas något kvar att utforska. Där emot tror att vi framöver kommer att få allt fler svar från allt fler perspektiv och att verktygen gör det allt enklare att navigera i denna information.
I många situationer kan vi få de svar vi söker ganska enkelt. I de situationer som vi inte finner precis de svar vi vill ha, måste vi utföra ett visst arbete för att nå svaren. Detta arbete kan vara av experimentell natur, att vi gör någon form av observation i verkligheten. Den information vi vill ha, kommer redan att finnas digitalt om än utspridd och ostrukturerad. Forskning kommer alltså i allt högre grad innebära sammanställning och organisering av redan befintlig data.
För att komma närmare målet tror jag att verktygen måste bli allt bättre på att ta tillvara all den kunskap som kan utläsas ur forskares och andras aktiviteter i informationsmiljön. När nästa person ställer samma fråga, ska han finna svaret (med motivering och källhänvisning) och inte behöva upprepa det redan utförda arbetet. Vidare kan mycket kunskap utvinnas från hur informationen sammanställs och hur forskaren värderar och behandlar det material han kommer i kontakt med under sitt sökande efter svaret. Vi lär upp informationsmiljön att forska i vårt ställe.
Den teknik bör användas, som ger störst tillfredsställelse för individen på kort sikt. Det är inte lätt att motivera någon att utföra en aktivitet på ett sätt som ger bättre resultat på lång sikt om aktiviteten går att utföra snabbare och enklare på annat vis. Därför bör utvecklingen av verktygen i informationsmiljön ske "på köpet". När altruistiskt sinnelag råder hos forskaren bör detta tillvaratagas effektivt. Det viktiga är att forskaren väljer att sammanställa informationen och bete sig på ett sådant sätt att de befintliga verktygen kan få ut så mycket kunskap som möjligt. I värsta fall får vi använda morot och piska, dvs ekonomisk och social belöning och bestraffning, för att styra forskarens beteende.
Våra verktyg kan alltid bli bättre. Vi kan ha verktyg som ger oss en viss grad av personanpassad information. När forskaren reagerar på denna information ska verktygen lära av detta så att det nästa gång ännu bättre kan urskilja vad som är intressant för honom och andra. Med enkla verktyg kan han behöva lägga ned tid och energi på att förbättra dess prestation. Alla tekniker som ökar verktygens anpassningsförmåga och intelligens bör kombineras så att de kommer allt närmare målet.
Våra verktyg idag har inte stor förmåga att ta till vara på den kunskap aktiviteterna i informationsmiljön förmedlar. Utvecklingen idag sker genom att programutvecklarna får synpunkter på sina produkter. Produkterna utvecklas sedan för att bättre göra det användaren önskar. Programmen blir alltså allt mera intelligenta. Anpassningsbarheten innebär idag att användaren kan konfigurera sina verktyg på ett enkelt sätt.
Utvecklingen mot målet kan ske stegvis genom att vi kan arbeta med verktygen på en allt högre abstraktionsnivå. I tidiga ordbehandlare var vi tvugna att tecken för tecken skapa våra innehållsförteckningar. Idag görs detta med kommandot "skapa innehållsförteckning". Om några år kommer motsvarigheten till MS Office "Wizards" tillåta användarna att göra ännu mera på en mer abstrakt nivå. I tidiga frågeverktyg var vi tvungna att ange kriterier på en detaljerad teknisk nivå och ofta upprepade gånger i olika miljöer. Nu blir sökverktygen på Internet allt bättre på att hitta de mest relevanta dokumenten för det vi vill ha. Konfigurationen av verktygen har blivit bättre genom att möjligheten att förändra beteendet dyker upp just när vi har intresse och behov av det, dvs första gången situationen uppkommer. Konfigurationsdialogen integreras med den aktivitet vi utför för tillfället och svaret sparas till nästa gång.
Själva verktygsutvecklingen flyter ihop med verktygen själva genom att ordbehandlare, databaser, html-editorer och programutvecklingsmiljöer integreras med varandra och med de färdiga produkterna. En aktivitet kan exempelvis starta en wizard där vi beskriver det resultat vi vill ha. Detta egenskapade verktyg kan sedan utvecklas vid behov när vi försöker göra nya saker med det. Med en ständig utveckling av verktygens intelligens, anpassnignsförmåga och utvecklingsbarhet kommer vi ständigt närmare målet. Med denna utveckling kan vi snart med ord beskriva vilka strategier vi använder för att uppnå ett visst mål. Informationsmiljön lär sig då strategierna och kan nästa gång själv utföra resonemangen i forskarens ställe.
Jag måste förtydliga att även om detta låter väldigt mycket som intelligenta agenter, etc, kan samma mål lika väl innebära en utveckling av verktygen för mänsklig kommunikation. Det kan även innebära nya riktlinjer för stadsarkitekturen, etc. En stor del av kunskapen är inte nedskriven. De bästa svaren kan vi ofta få muntligt från rätt person. Informationsmiljön kan alltså utvecklas till att hjälpa forskaren att finna rätt person och sedan erbjuda rätt sorts utrymme för samtalet.
Nu till ett exempel. En forskare studerar fotosyntes och hur industriutsläpp, etc påverkar processen. Fotosyntes och industriutsläpp utgör tillsammans ett relativt outforskat begreppskomplex. En del forskning (arbete) är gjort på området (kan vi låtsas). En stor effekt av utsläppen är att de påverkar mikroorganismer som har en viktig roll i fotosyntesen, och att detta tidigare missats. De kanske blockerar rötterna på något sätt som hindrar processen. Detta är ännu helt okänt.
Forskaren har bett om alla spekulationer kring kopplingen mellan industriutsläpp och fotosyntes. Många sådana spekulationer finns. En efter en tittar han på dessa spekulationer och finner dem ointressanta. I och med det slipper han detaljdiskussionerna på området, men får korta översikter över forskningens utveckling. Spekulationen om mikroorganismer fångar hans intresse. Någon kunskap om en sådan koppling finns inte idag. Hans direkta fråga ger alltså inget svar. Därför sätter han igång och sammanställer information. Han har frågan och målsättningen klar. Utifrån denna letar han på olika ställen och ställer olika delfrågor för att försöka hitta rätt. Utifrån resultatet av efterfrågningarna adderas begreppskonstellationen industriutsläpp - fotosyntes till de källor där ledtrådar till svaren finns. Detta gör att dessa källor kan presenteras för nästa person som är på jakt efter samma koppling. Huruvida källorna var av vikt kan verktyget se på det sätt som forskaren sparar informationen. Den information han samlar på sig organiserar han på sitt arbetsutrymme. Därav kan miljön utläsa på vilket sätt källan är intressant i sammanhanget. Potentiellt intressanta källor läggs i facket för "kanske intressant" och rankas därmed enligt detta, för andra forskare, tills dess informationen förkastas eller ges en klarare definition. Under arbetets gång får miljön en klar bild av vad forskaren kan, har för intressen och mål. Detta gör att andra forskare med liknande frågor lätt hittar rätt person att ta kontakt med.
När han funnit flera pusselbitar sammanställer han informationen genom att säga till verktygen att utföra olika operationer på materialet. Han säger exempelvis till datorn att plocka ut de orsakssamband eller tabeller eller liknande han är intresserad av. Han sammanställer texter och visar därmed att den långa texten kan sammanställas så som han gjort, och att denna sammanställningen är intressant utifrån det perspektiv andra kan ha när de söker svaret på den fråga han söker. På så vis fortsätter han att tvätta datan för att få fram det intressanta. Tvättningsprocessen medför att en massa kunskap skapas. Han fortsätter med att beskriva den resonemangsordning han vill använda sig av och hur de olika delarna hänger ihop. Utifrån detta sätts delarna samman. Han fortsätter att sammanställa materialet, inte genom att skriva ihop allt för hand, utan genom att steg för steg tala om varför han vill att slutresultatet ska se lite annorlunda ut, än det sätt som datorn satt samman det i föregående steg, så att dessa nya regler kan kopplas till ämnesområdet och så att slutresultatet blir som han vill ha det. När han är klar har han inte bara ett forskningsresultat. Han har även producerat en enorm mängd kunskap om begreppskonstellationen som verktygen kan använda för att nästa gång presentera liknande svar nästan av sig själv. Dessutom har han lärt verktygen de strategier han själv och andra kan använda nästa gång för uppsökandet och sammanställandet av kunskapen.
Ovanstående är en beskrivning av en tänkt framtida utveckling av en informationsmiljö ur det perspektiv en forskare kan tänkas ha. Jag vill undersöka vad andra forskare tycker om denna framtidsbild. För detta ändamål sammanfattade jag min framtidsbild till fem specifika egenskaper hos informationsmiljön. Utifrån dessa egenskaper kunde jag sedan formulera frågor. Det är min hypotes att forskarna är positivt inställda till de beskrivna egenskaperna.
Miljön ska förstå forskarens uttryckta vilja. Han ska så lite som möjligt behöva översätta sin tanke till en följd instruktioner anpassade för verktygens begränsningar. Exempel: Han vill att en text ska få plats på en fram och baksida på ett A4-papper. En intelligent miljö kan förstå denna instruktion och löser uppgiften på ett snyggt sätt. I en mindre intelligent miljö måste han för hand ändra textstorlek och marginaler.
Miljön ska anpassa informationsflödet efter forskarens önskemål. Han ska så lite som möjligt på egen hand behöva leta upp och sortera ut den information han är intresserad av. Exempel: Han vill ägna ca 10 minuter i veckan åt att läsa om utvecklingen av bemannade rymdstationer. En anpassningsbar miljö väljer ut precis den informationen han vill ha. I en mindre anpassningsbar miljö måste han själv gång på gång söka igenom en större mängd grovt sorterad information.
Miljön ska kunna utföra nya aktiviteter efter forskarens instruktioner. Han ska så enkelt som möjligt kunna instruera hur miljön ska utföra vad han vill. Exempel: Han vill finna adress och korta fakta om en viss person. En utvecklingsbar miljö instrueras enkelt hur han går till väga för att presentera informationen om personen. I en mindre utvecklingsbar miljö måste han varje gång själv utföra sökningarna med de olika verktyg som finns och sammanställa datan från de olika källorna.
Miljön ska osynligt lära sig av forskarens aktiviteter. Han ska så lite som möjligt behöva instruera, det miljön redan borde ha lärt sig. Exempel: Han vill börja varje morgon med att läsa världsnyheter. En lärande miljö vet att morgonnyheter efterfrågas utan att han uttryckligen behöver be om det. I en miljö utan lärande behöver han vid ett tillfälle särskilt instruera om vad det är han önskar.
Miljön ska tillåta skapande, kreativitet och kommunikation i alla lägen. Han ska så lite som möjligt hindras av upphovsmän, ägare, struktur, tid och plats. Exempel: Han upptäcker att ett stycke i ett dokument kan klargöras av en referens han känner till. I en kooperativ miljö kan han tillföra denna referens till stycket oavsett vem som äger det och hur det är lagrat. I en inte så kooperativ miljö måste han gå igenom en så långdragen process att han väljer att avstå.
För att undersöka hypotesen konstruerade jag en enkät och skickade denna med e-post till ett antal forskare. Under nedanstående rubriker beskriver jag urvalet av försökspersoner, konstruktion av enkäten och vald statistisk analysmetod.
För denna undersökning begränsade jag mig till forskare vid Göteborgs Universitet. Vid urvalet av forskare utgick jag från universitetets hemsida (http://www.gu.se/) och gick igenom alla institutioner på jakt efter forskare som visat intresse för sin egen hemsida. Mitt antagande var här att de som visat intresse för sin egen hemsida också har ett intresse för denna modernare informationsteknologi. Jag har inte haft tillfälle att pröva detta antagande.
Vissa institutioner saknade hemsida. Vid många andra institutioner kunde forskarna endast nås via e-post, eller så saknades en förteckning över forskarnas hemsidor. Forskare från dessa institutioner kom inte med i undersökningen.
Flera institutioner hade standardiserade webbsidor för sina forskare. I dessa fall valde jag ut de sidor som avvek från mängden genom extra material eller bilder.
Vid vissa institutioner fanns väldigt många webbsidor. Jag valde då ut de som speciellt utmärkte sig genom väl genomtänkt och rikligt innehåll och de med extra tekniska finesser.
Eftersom jag talat med många människor vid Institutionen för Informatik om denna uppsats har jag inte tagit med någon forskare därifrån.
Enkäten skickades ut med e-post till de utvalda forskarna den 30 april. Först i enkäten beskrevs vad jag ville komma åt. Det var tänkt att de som svarade på enkäten i tid var dels aktiva användare av informationsteknologin och dels intresserade av det ämne enkäten handlar om. De data jag fick borde alltså spegla de forskare med ett speciellt intresse för informationsteknologi. Någon annan ersättning för deras medverkan fanns inte.
Inga påminnelser skickades. Totalt svarade 30 forskare av 95 utvalda. Det motsvarar ett bortfall på 70 procent. Tabell 2 visar fördelningen av utvalda personer och andel som svarade vid de olika fakulteterna.
| Fakultet | Utvalda | Svarande |
|---|---|---|
| Medicin | 8 | 38% |
| Humaniora | 25 | 28% |
| Konst | 4 | 25% |
| Samhällsvetenskap | 12 | 33% |
| Matematik-naturvetenskap | 46 | 33% |
| Totalt | 95 | 32% |
De forskare jag valt ut fördelar sig troligen inte över de olika fakulteterna i proportion med antalet forskare som finns där. Om forskarnas inställning varierar mellan de olika fakulteterna, betyder en snedfördelning i urvalet att svaret inte blir representativt. För att säkra tillförlitligheten i undersökningen jämförde jag forskarnas inställning vid de olika fakulteterna. Tillförlitligheten hänger på att inga större skillnader finns mellan de olika fakulteterna. Resultatet av denna kontroll presenteras under rubriken Resultat.
Enkäten (bilaga 1) konstruerades som en Likert-skala enligt Patel och Davidson (1994) sid 70-73. För var och en av de fem egenskaperna formulerades sex påståenden. För var och ett av påståendena bads forskaren att ange om de "instämmer helt", "instämmer delvis", "är tveksam", "tar delvis avstånd" eller "tar helt avstånd". Hälften av påståendena formulerades i positiva ordalag och hälften i negativa ordalag. I de positivt formulerade påståendena motsvarar "instämmer helt" 5 poäng och "tar helt avstånd" 1 poäng. Poängsättningen är omvänd för de negativt formulerade påståendena. Anledningen till att blanda positivt och negativt formulerade frågor är att undvika enkla tendenser i svarandet, som att rakt igenom svara "instämmer helt".
När jag i det följande skriver att en forskare instämmer helt i ett påstående, menar jag att forskaren fick 5 poäng. Vi bortser alltså från att hälften av påståendena var formulerade i negativa ordalag.
Ett värde för en forskares inställning till en viss egenskap kan fås genom att summera svaren på de sex påståendena och dividera med antalet svar. På så vis kan man få ett jämförbart värde även för de som inte svarat på alla av de sex påståendena. Samtliga poäng kan räknas samman och divideras med antalet svar för att ge en övergripande poäng för inställningen till hela konceptet.
Målet var att mäta forskarens inställning till en utopi. Men det är nödvändigt att ha kortfattade och tydliga påståenden för att göra det enkelt att snabbt svara på dem. Det skulle ta många rader att beskriva bakgrunden till en utopisk situation för forskaren att ta ställning till. Därför var jag tvungen att konstruera enkätens påståenden utifrån situationer jag kunde antaga att forskaren var bekant med. Jag valde därför att formulera påståendena under fyra rubriker, vilka fick utgöra kontexten för påståendena. Dessa var "Ordbehandlingsprogram", "World Wide Web", "Kommunikationsprogram" och "övrigt". De 30 påståendena fördelades jämt under de olika rubrikerna så var och en av de egenskaper jag ville mäta fick sitt värde från påståenden under flera rubriker. Rubrikerna hade dessutom en funktion för att avleda uppmärksamheten från de egenskaper jag ville mäta. På så vis kunde inte forskaren med enkelhet identifiera vilka frågor som hörde till vilka egenskaper och anpassa sitt svarande efter detta.
Frågorna utprovades på ett par studenter. Där varierade attitydpoängen mellan 2,2 och 5,0. Normalt ska man pröva att de som får höga poäng på enkätundersökningen verkligen är positivt inställda till utopin. Det skulle kunna göras genom att jämföra enkätresultaten med djupintervjuer under en pilotstudie. Någon sådan prövning av enkätens validitet har jag inte haft resurser att genomföra. Resultatet hänger därmed på att enkäten verkligen utgör ett mått på inställningen till den beskrivna framtidsvisionen.
Enkäten är utformad efter den omvända tratt-tekniken (Patel & Davidson, 1994. sid 65). Först beskrivs syftet med enkäten. Därefter kommer ett par frågor som forskaren borde kunna svara på med enkelhet. Efter alla attitydfrågor, då forskaren hunnit tänka sig in i vilka åsikter han har om ämnet, ges han tillfälle att komma med egna synpunkter.
I början av enkäten fick de ange om de ville att deras svar skulle behandlas konfidentiellt. Namnen på dessa byttes ut till ett nummer. Sist i enkäten fick forskaren uttrycka egna önskemål. De som medgivet citering finns att läsa i bilaga 3.
Frågorna var formulerade så att en forskare med positiv inställning till egenskaperna borde instämma i alla delfrågorna. Fyra poäng ges för ett delvist instämmande och fem poäng för ett helt instämmande. En forskare med positiv inställning till alla egenskaperna får därmed ett medelvärde på mellan 4 och 5.
Jag har en huvudhypotes och fem sekundära hypoteser att pröva. För det första; är majoriteten av forskarna positivt inställda till den beskrivna visionen? För det anda; är majoriteten av forskarna positivt inställda till var och en av de fem beskrivna egenskaperna? Detta beräknas genom att summera antalet personer med en poäng på 4,0 eller mera och dividera med totala antalet försökspersoner.
För att avgöra reliabiliteten av undersökningsresultatet gjorde jag en beräkning av konfidensintervallet (Ejlertsson 1992). Värdet på de intresserade forskarnas inställning till utopin är beräknat utifrån ett stickprov ur den fulla populationen av alla intresserade forskare. Det verkliga värdet kan endast fastställas genom att undersöka alla intresserade forskare. Konfidensintervallet är det intervall inom vilket det sanna värdet med en viss sannolikhet befinner sig. Formeln för denna beräkning (för det fall då både medelvärde och standardavvikelse skattats utifrån stickprovet) fick jag från Tommy Johansson vid statistiska institutionen, Handelshögskolan, Göteborgs Universitet.
Formeln för konfidensintervallet är , där n är storleken på stickprovet och
p-tak den beräknade andelen. Värdet 1,96 ger
konfidensintervallet för en sannolikhet på 95%.
27 procent av forskarna visade sig ha en positiv inställning till de beskrivna egenskaperna. På grund av att värdet baseras på en såpass liten grupp är konfidensintervallet ganska stort. Det sanna antalet positivt inställda forskare ligger med 95% sannolikhet mellan 11 och 43 procent. Vi kan därmed sluta oss till att en majoritet av forskarna inte är positivt inställda till den beskrivna informationsmiljön i allmänhet.
Det finns en stor variation i inställningen mellan de olika egenskaperna. Utvecklingsbara och intelligenta program fick positivt bemötande. Självlärande program och kooperativa miljöer var inte populära. Se bilaga 2 för en detaljerad redovisning av enkätsvaren.
| Egenskap | Andel positiva | Konfidensintervall |
|---|---|---|
| Intelligens | 57 % | ± 18 % |
| Anpassningsförmåga | 30 % | ± 17 % |
| Utvecklingsbarhet | 73 % | ± 17 % |
| Lärande | 17 % | ± 14 % |
| Kooperativitet | 17 % | ± 14 % |
| Totalt | 27% | ±16% |
Medelvärdet för forskarens inställning till egenskaperna skiljer sig bara marginellt mellan de olika fakulteterna. (Se tabell 4) En eventuell snedfördelning har därmed troligen ingen inverkan på resultatet.
| Medicin | 3,4 |
| Humaniora | 3,6 |
| Konst | 2,9 |
| Samhälle | 3,8 |
| Natur | 3,5 |
| Totalt | 3,6 |
|---|---|
Av svaren på enkäten visade det sig att flera ansåg frågorna svåra att svara på. En del reagerade med att svara med frågetecken. Det är möjligt att andra svarade med tveksam-alternativet. Detta medför att resultatet förskjutits något mot 3,0.
I slutet av enkäten fick forskarna ge egna förslag på framtidens informationsmiljö. Den mest efterfrågade förändringen var att alla vetenskapliga artiklar inte bara ska vara elektroniskt sökbara, utan också nedladdnignsbara från Internet. För en fullständig redovisning av förslagen, se bilaga 3.
Forskarna var positivt inställda till intelligenta och utvecklingsbara program, men inte till den beskrivna miljön i allmänhet.
Jag tror att de låga värdena på anpassningsbarhet och lärande till stor del beror på att forskaren inte vill förlora kontrollen till datorn. De vill inte att ett program ska omsätta något de lärt till en handling utan att först få klartecken från forskaren. Den får inte ta egna initiativ. Jag tror att den motvilja som visade sig beror på att frågorna formulerades just som att datorn gjorde saker på egen hand. Det kunde tolkas som om den gjorde sakerna utan att först rådfråga forskaren, vilket inte var min mening. Men resultatet visar dock på en vilja att själv behålla kontroll och initiativet.
Resultatet kan också visa på en vilja att behandla datorn som ett verktyg. Ett verktyg kommunicerar man inte med. Ett verktyg tar inga egna initiativ eller lever sitt eget liv. Ett verktyg är en förlängning av forskarens egna sinnen och utveckling av forskarens egna händer. Ett verktyg ska helst vara en osynlig länk mellan forskaren och objektet de fokuserar på. En sådan inställning kan leda till en negativ inställning till informationssystem som drar uppmärksamhet till sig.
På liknande vis verkar det låga värdet för kooperativitet ha att göra med att forskaren vill behålla kontrollen över sitt egna material. Ingen utomstående ska få se eller modifiera något utan forskarens uttryckliga tillåtelse. Ovilja att kommunicera var det inte. Flera forskare kom med förslag på förbättrade kommunikationsmöjligheter.
En del forskare svarade också att de inte trodde att datorerna skulle kunna bli tillräckligt bra för att på ett tillfredsställande sätt fungera så som beskrivits. (Se bilaga 3.)
Flera forskare hade synpunkter på påståendenas utformning. Exempelvis menade några att negerade påståenden är förvirrande och att en del påståenden handlar om saker som förutsätter kunskap om specifika programprodukter (exempelvis MS Word), vilket inte alla har. Påståendena kunde ha konstruerats för att bättre bemöta dessa problem än vad som gjordes vid denna undersökning.
Min önskan var att undersöka hur en utopisk informationsmiljö skulle se ut. Det gjorde jag genom att pröva en hypotes. Ett sätt att gå vidare skulle kunna vara att utföra djupintervjuer med ett antal forskare, exempelvis de fem mest positiva och de fem mest negativa, för att lära mer om vad de grundar sin inställning på.
Alla länkar fungerade 1997-05-22.
FORSKARENS UTOPIA Jag skrev för en tid sedan och bad om en intervju. Men det visade sig att den metoden inte skulle hålla för den tidsram jag har. Jag har därför omformat intervjun till en enkät som jag här skickar till er. Jag ber er att spendera ett par minuter med att svara på detta brev. MIN DRöM är en värld där jag direkt kan få vad jag önskar, allt snabbt som tanken. Livet blir ett skapande äventyr. Vi målar alla vackra landskap med våran tankevärld. Att nå information om en sak ska inte ta längre tid än att formulera just vad det är man vill veta. Att skapa något ska inte kräva mer arbete än att beskriva vad man vill ha. Jag vill här se vad andra har för vision om framtiden. Närmare bestämt hur forskare skulle vilja ha sin informationsmiljö. Med informationsmiljö menar jag den information du får från prenumererade tidskrifter, bibliotek, konferenser, fikapauser, osv. Ingen av dessa informationskanaler är perfekta. Skulle en av dem vara perfekta skulle vi inte behövt de andra av dem. Just vilka egenskaper hos dessa informationskanaler är det vi vill åt? Släpp tankarna fria och bry dig inte om vad som är tekniskt möjligt idag. Föreställ dig att allt som föreslås nedan fungerar alldeles utmärkt. Då börjar vi. Skriv antingen svaret i anslutning till frågan eller ange numret på den fråga du svarar på. 1. Vill ni vara anonym? 2. Får jag citera från era svar? 3. Vad är titlarna på era avklarade och/eller framtida doktorsavhandlingar? 4. Beskriv erat forskningsområde kortfattat. Nedan finns en rad påståenden. Vi ber dig att spontantant ta ställning till varje påstående och markera din inställning med att skriva in motsvarande förkortning för det alternativ som bäst stämmer överens med din uppfattning. Instämmer helt ( IH ) Instämmer delvis ( ID ) Tveksam ( T ) Tar delvis avstånd ( TDA ) Tar helt avstånd ( THA ) ORDBEHANDLINGSPROGRAM 5. Jag vill skriva in min innehållsförteckning för hand, snarare än att låta programmet automatiskt generera en. (IH, ID, T, TDA, THA) 6. Jag vill kunna anpassa knappraden så att den innehåller de funktioner jag använder oftast. (IH, ID, T, TDA, THA) 7. Jag vill att datorn ska lära sig var jag vill spara det det dokument jag arbetar med utifrån vad det handlar om. (IH, ID, T, TDA, THA) 8. Jag har inget intresse av att skapa macros för de procedurer jag upprepar ofta i ordbehandlingsprogrammet. (IH, ID, T, TDA, THA) 9. Om jag använder den kontinuerliga rättstavningsfunktionen ofta vill jag kunna ställa in att den "default" är påslagen. (IH, ID, T, TDA, THA) 10. Jag vill kunna säga till datorn att anpassa mitt dokumentet så att det passar lagom på en fram och baksidan på ett A4-papper. (IH, ID, T, TDA, THA) 11. Jag vill inte att programmet själv anpassar knappraden efter de funktioner jag brukar använda. (IH, ID, T, TDA, THA) WORLD WIDE WEB 12. Jag vill inte att någon annan ska kunna kommentera det jag skrivit, så att alla som läser det jag skrivit också kan läsa kommentarerna. (IH, ID, T, TDA, THA) 13. Jag vill inte att programmet själv väljer den bästa sökmotorn för det jag vill finna. (IH, ID, T, TDA, THA) 14. Jag vill kunna byta ut eller utöka delar av browsern med programmoduler utvecklade av mig själv eller någon annan. (IH, ID, T, TDA, THA) 15. Jag vill att min browser sorterar onumrerade listor av länkar så att de som mest överensstämmer med mina intressen kommer överst. (IH, ID, T, TDA, THA) 16. Jag vill att min browser själv håller reda på de sidor jag besöker, hur lång tid jag spenderar på dem, hur ofta jag återbesöker dem, etc och utifrån detta sorterar upp en personlig bokmärkesdatabas på ett intelligent sätt. (IH, ID, T, TDA, THA) 17. Jag vill inte att den text jag läser automatiskt ska omformas så att de ord jag inte förstår beskrivs på ett för mig anpassat vis. Jag föredrar att själv slå upp de ord jag inte förstår. (IH, ID, T, TDA, THA) 18. Jag vill enkelt kunna instruera datorn om hur den ska leta reda på data om en viss person, exempelvis genom att söka igenom ett antal söktjänser på ett speciellt sätt. (IH, ID, T, TDA, THA) 19. Jag föredrar att skriva in hela URL:en till den sida jag söker. Jag vill inte att programmet ska fylla på med "http:", "www", etc. (IH, ID, T, TDA, THA) 20. När jag ser ett stavfel i ett dokument på www vill jag gärna enkelt kunna rätta till det. (IH, ID, T, TDA, THA) 21. Jag vill inte att browsern ändrar på bakgrundsmönster, färg och fontstorlek för att den av erfarenhet vet att jag har svårt att läsa med den färgkombinationen. (IH, ID, T, TDA, THA) KOMMUNIKATIONSPROGRAM 22. Jag föredrar att själv läsa igenom mängder med osorterade nyhetsrubriker. Jag vill inte att datorn väljer ut de mest intressanta för mig. (IH, ID, T, TDA, THA) 23. Jag vill ha en adressbok till mitt emailprogram så att jag slipper skriva in emailadresserna för hand. (IH, ID, T, TDA, THA) 24. Jag vill kunna beskriva hur varje nytt brev ska behandlas, utifrån dess innehåll. Dvs om det ska betraktas som viktigt eller oviktigt, om det ska skickas vidare någonstans, osv. (IH, ID, T, TDA, THA) 25. Jag vill själv starta upp mitt mailpropgram varje morgon. Datorn ska inte få dra några egna slutsatser och göra det åt mig, även om jag alltid börjar morgonen med att läsa mail. (IH, ID, T, TDA, THA) 26. Jag vill kunna skicka ett e-post på 5 sekunder, även när jag är utomhus.(IH, ID, T, TDA, THA) 27. Jag är fullt nöjd med mina kommunikationsprogram och vill inte förbättra något. (IH, ID, T, TDA, THA) 28. Det gör inget att det inte går att få tag på upphovsmännen till många webbsidor. (IH, ID, T, TDA, THA) 29. Andra personers mailprogram får gärna ta del av den sortering jag gör av de nyheter jag läser, så att de lättare ska finna vad som är intressant. (IH, ID, T, TDA, THA) öVRIGT 30. Jag skulle gärna vilja kunna prata med datorn. (IH, ID, T, TDA, THA) 31. Om jag märker att datorn inte klarar av det jag vill göra, är det okej. Att den skulle söka upp och installera rätt program för att lösa problemet är inte av intresse. (IH, ID, T, TDA, THA) 32. Jag vill inte att datorn räknar ut en intresseprofil utifrån de dokument jag läser, så att andra med liknande intresse kan få kontakt med mig. (IH, ID, T, TDA, THA) 33. Jag vill alltid göra min egen sammanställning av den information jag söker. Ett program som letar upp och samanställer informationen speciellt anpassat för mig är inte av intrese. (IH, ID, T, TDA, THA) 34 Det är jobbigt att konfigurera alla program jag ska använda. Jag skulle vilja att programmet själv fattade hur jag ville ha det konfigurerat. (IH, ID, T, TDA, THA) Slutligen: 35. Nämn något du skulle önska att en framtida informationsmiljö för forskning skulle ha. 36. är det något mer du vill säga?
Antal svarande försökspersoner: 30
Betydelse av bokstavsbeteckningarna:
| I | A | U | L | K | Totalt | |
|---|---|---|---|---|---|---|
| Medelvärde | 3.91 | 3.45 | 4.19 | 3.10 | 3.08 | 3.55 |
| Standardavvikelse | 1.37 | 1.51 | 1.04 | 1.55 | 1.47 | 1.46 |
| Antal positiva | 17 | 9 | 22 | 5 | 5 | 8 |
| Procent positiva | 57% | 30% | 73% | 17% | 17% | 27% |
| Konfidensintervall | 18% | 17% | 16% | 10% | 14% | 16% |
| Påståendets nummer | Var påståendet positivt eller negativt formulerat? | Vilken egenskap skulle påståendet mäta? | Procent positiva | Antal positiva | Medelvärde | Standard- avvikelse | Antal forskare som svarade på påståendet |
|---|---|---|---|---|---|---|---|
| 5 | - | I | 59% | 17 | 3.48 | 1.62 | 29 |
| 6 | + | A | 86% | 25 | 4.41 | 1.02 | 29 |
| 7 | + | L | 60% | 18 | 3.60 | 1.43 | 30 |
| 8 | - | U | 63% | 19 | 3.83 | 1.29 | 30 |
| 9 | + | A | 69% | 18 | 4.00 | 1.36 | 26 |
| 10 | + | I | 83% | 25 | 4.40 | 1.13 | 30 |
| 11 | - | L | 31% | 9 | 2.79 | 1.40 | 29 |
| 12 | - | K | 26% | 7 | 2.78 | 1.25 | 27 |
| 13 | - | I | 40% | 12 | 3.30 | 1.24 | 30 |
| 14 | + | U | 93% | 28 | 4.60 | 0.62 | 30 |
| 15 | + | A | 70% | 21 | 3.87 | 1.36 | 30 |
| 16 | + | L | 67% | 20 | 3.57 | 1.50 | 30 |
| 17 | - | A | 21% | 6 | 2.00 | 1.31 | 29 |
| 18 | + | U | 90% | 26 | 4.45 | 0.78 | 29 |
| 19 | - | I | 73% | 22 | 3.90 | 1.40 | 30 |
| 20 | + | K | 37% | 10 | 2.74 | 1.58 | 27 |
| 21 | - | L | 17% | 5 | 2.24 | 1.38 | 29 |
| 22 | - | A | 52% | 15 | 3.21 | 1.42 | 29 |
| 23 | + | I | 100% | 30 | 4.97 | 0.18 | 30 |
| 24 | + | U | 80% | 24 | 4.30 | 1.06 | 30 |
| 25 | - | L | 40% | 12 | 2.77 | 1.77 | 30 |
| 26 | + | K | 55% | 16 | 3.69 | 1.37 | 29 |
| 27 | - | U | 70% | 21 | 4.03 | 1.03 | 30 |
| 28 | - | K | 63% | 19 | 3.93 | 1.14 | 30 |
| 29 | + | K | 31% | 9 | 2.79 | 1.37 | 29 |
| 30 | + | I | 50% | 15 | 3.37 | 1.40 | 30 |
| 31 | - | U | 67% | 20 | 3.93 | 1.17 | 30 |
| 32 | - | K | 27% | 8 | 2.47 | 1.53 | 30 |
| 33 | - | A | 53% | 16 | 3.27 | 1.36 | 30 |
| 34 | + | L | 60% | 18 | 3.60 | 1.35 | 30 |
Datorer är ett utmärkt redskap, men det är
jag som skall bestämma, inte den, eftersom jag är
mycket klokare. Böcker och eget tänkande är i längden alltid
viktigare än dataprogram. Forskare som använder tid på att
perfektionera söksystemen gör det som regel för att de inte
vet vad de letar efter. Flertalet är som regel dåliga
forskare. De verkligt bra forskarna finner vad de söker, även
om de måste famla sig fram i söksystemen.
Bättre databaser där t ex alla avhandlingar låg Att man kunde
scanna in resultaten av enkätundrsökningar så man slapp koda
och stansa in dem.
Jag vill gärna kunna bära med mig datorn, eller en terminal som är kopplad till datorn, som en mobiltelefon s att jag kan sola och jobba vid datorn samtidigt.
Ett ordbehandlingsprogram som man kan tala in texten i vore
också trevligt.
- Möjlighet att skicka enkelt skicka dokument mellan olika typer av datorer i hela världen. Det går ganska lätt med text, men grafik är mycket svårare eftersom det finns så många format. Program som Adobe Acrobat kommer väl delvis runt detta problemm, eftersom allt översätts till ett gemensamt format. Men kvalitén tror jag blir lidande. Möjligheter att bolla dokument är oerhört viktigt när man är många författare på en artikel.
- En sökfunktion på WWW där man kunde hitta alla som jobbar med liknande saker som en själv.
- En databas med alla världens växter och djur, med bilder, utbredningskartor, uppgifter om ekologi mm.
- Egna chat-linjer för diskussion av projekt. Skulle spara
många flygresor.
Stoerre moejlighet att kunna koppla in sig mot "superdatorer" daer man kan koera stora analyser som tar alldeles foer laang tid paa vanliga persondatorer eller de "workstations" som man vanligen har tillgaang till.
Att internetprogrammen (aeven andra program tex excel) skulle bli "stabilare" och ej "bomba" lika ofta som de goer nu - det aer jaekligt irriterande naer man anvaender olika program samtidigt och internet eller excel sabbar allt. Dessutom borde det bli laettare att flytta data mellan olika programvaror, det kan staella till stora problem naer man anvaender sig av maanga olika programvaror foer att slutfoera ett dokument eftersom de aer olika bra paa olika funktioner.
Ett av de stora problemen med dagens infromationsmiljoe aer att vi har foer mycket infromation att vaelja mellan och det laer bli aennu vaerre i framtiden eftersom vi blir fler och fler maenniskor paa jorden och tenderar att bli mer vaelutbildade. Samtidigt vill jag inte gaerna ha naagra filter som sorterar infromationen automatiskt, anser att en maskin inte skall faa fatta beslut om vad foer information jag skall faa. Maskinerna boer inte faa makten over informationsfloedet till oss.
Ett annat problem inom forskningen som knappast kan vara nytt
aer att ifall man aer tillraeckligt kaend kan man publicera
"tack vare gamla bedrifter", men foer andra kan det vara
desto svaarare. Stoeld av ideer, eller foer att uttrycka det
paa ett annat saett - refusering av manuskript foer att sedan
ta till det sig som sin egen ide aer ocksaa ngt som tyvaerr
foerekommer. Vad jag skulle oenska vore att alla manuskript
borde granskas utan att "granskarna" vet vem/vilka som aer
foerfattare, paa saa vis skulle man kunna faa en mer objektiv
granskning av manuskript och inte gynnas av ev.
"kaendisskap".
Jag är myckat tveksam till att lämna ut för mycket data och
profiler om mig själv eftersom det snart kommer att utnyttjas
av kommersiella program ("spam mail") som dränker en med
fåniga erbjudaden om produkt X eller kedjebrev Y.
Att det skall vara så jobbigt/omöjligt som det är är faktiskt pinsamt! Att det inte fungerade 1986-1988 när allt var nytt kan vara OK, men det är 10 år sedan! Jag borde till exempal kunna stämpla en fil "postscript" så fattar macen att det är en ps fil.
Alltså: enhetliga standarder som kan transformeras fram o tillbaka.
Men det kanske är utopiskt.
II. Videokamera kopplad till varje dator och bredbandsförbindelser för att underlätta möten på distans.
III. Trådlös förbindelse (ex GSM system) med mycket små bärbara enheter där t.ex. e-mail talas in och som helt styrs med rösten för att slippa problemet med tangentbord.
IV. E-mail protokoll som tillåter med avancerad överföring av t.ex. formatterad text och bilder.
V. Snabbare dataförbindelser, kanske med möjlighet till viss trafikprioritering.
VI. Program som automatiskt känner av kommunikationsprotokoll och anpassas därefter, t.ex. vid seriell kommunikation med vetenskapliga instrument.
VII. Större möjligheter att utnyttja datorstödd utbildning inom universitetet. Innebär att mer ekonomiskt stöd måste ges till lärare som vill utveckla tillämpningar, stöd till mjuk- och hårdvara, och utbildning av universitetslärare. I en framtid med fler studenter och färre lärare är detta den mest effektiva vägen att lösa en svår ekvation.
I en tid där stora ansträngningar görs för att öka
tillgängligheten på information med databaser, sökmotorer
etc. är det viktigt att komma ihåg att en mycket kraftig
begränsning i "informationskedjan" är sista ledet, d.v.s. när
den sökta, redigerade och nedladdade informationen ska
överföras till hjärnan.
Forskarsamhällets plikter gäller forskning, undervisning och
information. De båda sistnämnda kan man utnyttja WWW i mycket
högre grad än vad som görs i dag. Vi har gjort ett först steg
i den riktningen, se
http://www.physiology.gu.se/cirk/bh/sve/fysiol.htm
Min tveksamma inställning till automatisering av många
funktioner beror på att jag är skeptisk angående hur
intelligent en dator kan bli. Till exempel: jag vill inte ha
mina bokmärken sorterade efter besöksfrekvens, utan efter
ämne. Hur långt måste utvecklingen gå innan en dator på egen
hand kan förstå vilket ämne jag skulle sortera en viss
Web-sida under?
Jag önskar att datoranvändningen skulle ha egenskap att välja rätta verktyg till rätt problem. Lika lite som jag tar fram köksmaskinen för att vispa ihop en omelett eller stora verktygsmaskinen för att slå i en spik, like lite tycker jag att man ska behöva öppna ett jätteprogram för att skriva ett litet stycke text. Tacka vet jag gamla goda ordbehandlingsprogram som kunde köras disklöst och tyst. Hur många av de finesser som finns i Word används verkligen på riktigt? Hur många av det "attached Word documents" jag får innehåller verkligen något annat än "råtext".
Ordbehandlaren får gärna gissa var jag skall lägga filer. Förr i tiden brukade de gissa att man ville lägga tillbaka i närheten av den fil man just öppnade - ganska intelligent faktiskt, till skillnad från dagens Word. "Mina dokument" - det är ju så gulligt att man kan spy!
Vad kostar det med alla uppdateringar? Jag skulle önska att
vi hade ett sätt att analysera kostnader för olika
arrangemang av beräknignsmiljöer - "small is beautiful" eller
BiB? Vad är lagom stora enheter?
2. System för automatisk konfigurering av flera datorer på
samma sätt (jobb, hemma, portabel), uppdatering av
adressregister, senaste brev, rättstavningsfiler mm.